DFlash: Block Diffusion for Flash Speculative Decoding
论文链接:https://arxiv.org/pdf/2602.06036
代码链接:https://z-lab.ai/projects/dflash
摘要
自回归大语言模型(LLM)性能优异,但其固有的顺序解码机制导致推理延迟高、GPU 利用率低。推测性解码通过使用快速 draft 模型来缓解这一瓶颈,该 draft 模型的输出由目标 LLM 并行验证。然而,现有方法仍然依赖于自回归 draft 生成,这仍然是顺序的,限制了实际加速的提升。Diffusion LLM 通过实现并行生成提供了一种很有前景的替代方案,但当前的 Diffusion 模型通常不如自回归模型。本文提出了一种推测性解码框架 DFlash,它采用轻量级块扩散模型进行并行 draft 生成。我们证明,推测性解码为扩散模型提供了一个自然且有效的设置。DFlash 通过在单次前向传播中生成草稿 token 来实现高效的草稿生成,并通过基于从目标模型中提取的上下文特征来调整草稿模型,从而获得具有更高接受率的高质量草稿。实验表明,DFlash 在各种模型和任务中实现了 6 倍以上的无损加速,比最先进的推测解码方法 EAGLE-3 的速度提高了 2.5 倍。
1.介绍
大语言模型(LLM)催生了众多强大的应用,包括对话 Agent 和自动化编程工具。尽管 LLM 取得了成功,但其推理仍然主要依赖于逐 token 生成的顺序过程,每个输出都依赖于完整的上下文。这种固有的串行性造成了严重的性能瓶颈:推理速度慢、内存占用高,并且无法充分利用现代 GPU 的性能。随着长思维链推理(CoT)模型的出现,这一瓶颈变得日益严峻,因为长时间的推理已成为生成过程的主要障碍。
推测性解码已成为解决这一瓶颈的主要方案。该范式采用轻量级草稿模型来推测未来 token 序列,然后由大型目标 LLM 并行验证这些 token。虽然这种方法实现了无损加速,并且已被广泛集成到生产框架中,但像 EAGLE-3 这样的最先进方法仍然依赖于自回归草稿。这种串行草稿过程不仅效率低下,而且容易累积错误,这有效地将可实现的加速限制在大约 2-3 倍。
近年来,扩散语言模型(dLLM)通过实现并行文本生成和双向上下文建模,为自回归语言模型提供了一种很有前景的替代方案。块扩散模型可以同时对一组被掩码 token 进行去噪。然而,目前开源的 dLLM 在生成质量方面通常不如自回归语言模型。此外,为了保持可接受的输出质量,通常需要大量的去噪步骤,这会显著降低其原始推理速度。
这种现状揭示了一个关键的权衡:自回归模型性能卓越,但存在顺序延迟;而扩散模型虽然能够实现快速并行生成,但往往会牺牲精度。由此自然引出一个研究问题:我们能否结合两种范式的优势,同时弥补各自的不足?一个引人注目的解决方案是利用扩散模型进行高速并行草图绘制,同时依靠高质量的自回归模型进行验证,以确保最终输出无损。
然而,利用扩散进行草稿生成并非易事,现有方法要么不切实际,要么加速效果有限。例如,DiffuSpec 和 SpecDiff-2 等方法使用大规模(例如,7B 参数)草稿模型。如此巨大的内存占用对于实际应用而言往往成本过高。此外,虽然这些大型草稿生成器能够提供相对高质量的草稿 token 和较长的接受长度,但较高的草稿延迟限制了其实际加速效果,使其仅为 3-4 倍。相比之下,PARD 训练小型自回归模型来模拟扩散式并行生成,然后对目标 LLM 进行推测性解码。然而,由此产生的小型模型缺乏目标 LLM 的建模能力,导致接受长度有限,加速效果也仅约为 3 倍。
Is there truly “no free lunch”? Can we build a diffusion drafter that is both lightweight and highly accurate?
本文介绍了一种名为 DFlash 的推测性解码框架,它使用轻量级块扩散模型来实现快速且高质量的草稿生成。我们的核心思想很简单:目标模型最了解情况。正如 Samragh et al. (2025) 所观察到的,大型自回归 LLM 的隐藏特征隐含地包含了关于多个未来 token 的信息。DFlash 利用这些隐藏特征作为上下文,使草稿模型能够并行预测未来的 token 块。实际上,草稿模型变成了一个 diffusion adapter,能够高效地利用大型目标模型所建模的深层上下文特征。DFlash 无需小型草稿模型从头开始推理,而是将目标模型的推理能力与小型扩散草稿器的并行生成速度融合在一起。
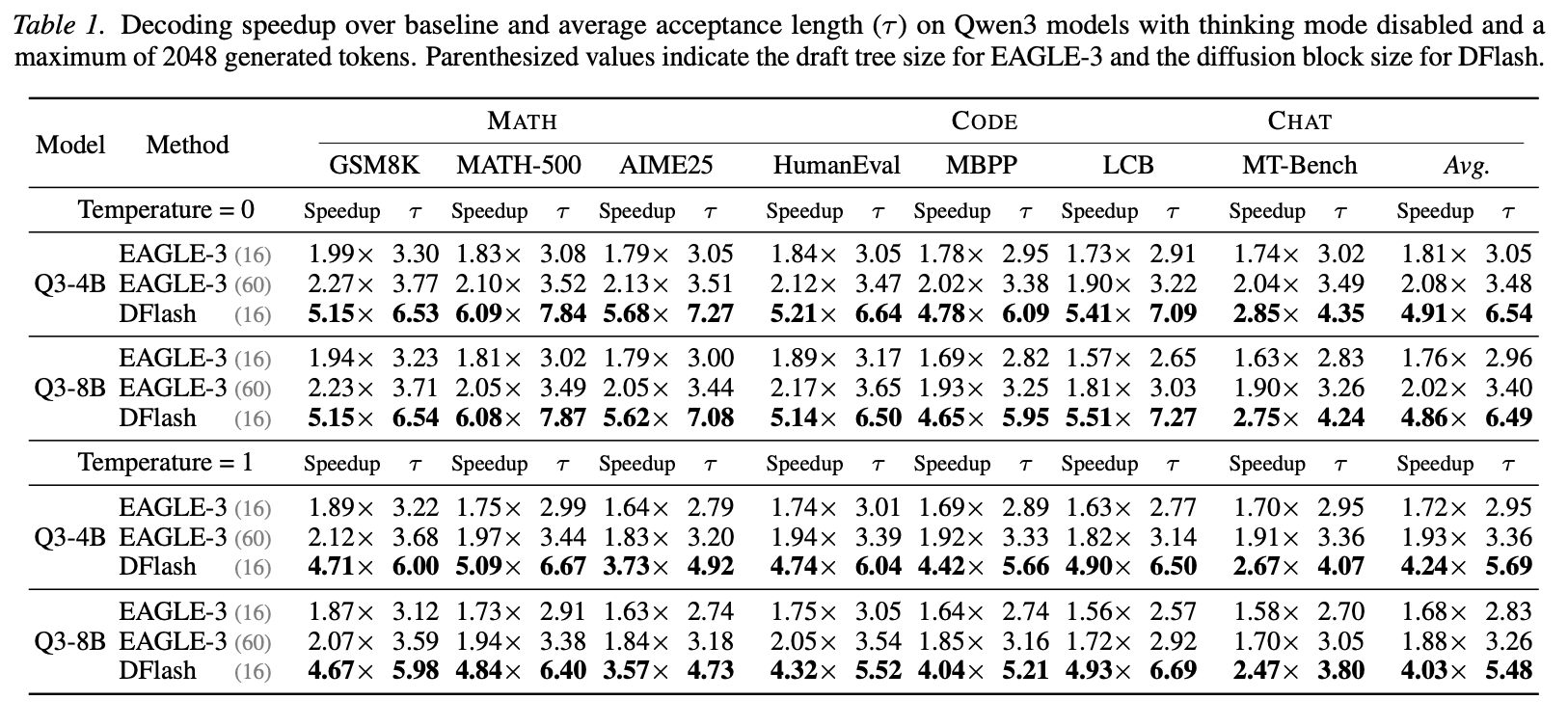
我们使用多种模型和基准测试对 DFlash 进行了评估,并在实际服务环境中使用 SGLang 展示了其实际优势。如图 1 所示,DFlash 在 Qwen3-8B 上实现了高达 6.1 倍的加速,并且在大多数基准测试中比目前最先进的 EAGLE-3 快近 2.5 倍。我们相信,DFlash 代表着在加速 LLM 推理和普及高性能 AI 方面迈出的重要一步。
2.Related Work
2.1 Speculative Decoding
推测性解码通过缓解自回归生成的序列瓶颈来加速 LLM 推理。早期方法采用较小的草稿模型来生成 token 序列,并由较大的目标模型并行验证这些序列。Medusa 通过在基础 LLM 中添加多个预测头并使用树注意力机制进行并行验证,消除了外部草稿模型。EAGLE 系列通过利用冻结目标模型中的特征级上下文信息进一步改进了推测性解码。EAGLE-1 预测未来的隐藏状态分布以提高接受率,EAGLE-2 引入了自适应草稿树,而 EAGLE-3 则优化了训练目标以进一步提升速度。
尽管取得了这些进步,但大多数现有方法依赖于自回归草稿,而自回归草稿本质上仍然是顺序的,这限制了它们的加速。
2.2 Diffusion Language Models
Diffusion large language models (dLLMs) 通过并行预测 mask token,为自回归生成提供了一种替代方案。LLaDA 是第一个将 dLLM 扩展到数十亿参数的模型,其性能与 LLaMA-3.1-8B 相当。然而,完全并行的扩散模型存在生成长度固定且缺乏高效 key-value 缓存支持的问题。块扩散模型通过逐块去噪序列来解决这些问题,将并行性与自回归结构相结合。基于此思想,Fast-dLLM v2 和 SDAR 将预训练的自回归 LLM 适配为块扩散变体,从而在特定任务上实现并行生成并保持生成质量。尽管如此,现有的 dLLM 通常性能不如最先进的自回归模型,并且通常需要大量的去噪步骤,这限制了它们的实际推理速度。
2.3 Diffusion-based Speculative Decoding
最近的研究探索了将扩散模型用作推测性解码中的草稿生成器。TiDAR 联合训练扩散和自回归目标,从而能够通过扩散进行并行“思考”,并通过自回归解码进行顺序“表达”,但最终生成的质量尚未达到无损水平。
其他方法则将自回归模型重新用于扩散式 draft 模型。Samragh et al. (2025) 指出,自回归 LLM 隐式地编码了未来 token 信息,并训练了一个 LoRA 适配器来实现并行 draft 解码,同时保留了用于验证的基础模型。
DiffuSpec 和 SpecDiff-2 采用大型预训练的 dLLM 作为推测性草稿器,并结合推理时搜索或训练-测试对齐来提高接受率。然而,这些方法依赖于庞大的草稿器(例如,7B 参数),导致大量的内存和延迟开销。虽然它们能够实现较长的接受长度,但高昂的草稿成本往往会抵消实际服务场景中的速度提升。
3.Preliminaries
本节正式阐述了推测性解码的加速机制,并阐明了自回归和基于扩散的草稿生成方式之间的效率权衡。我们的分析突显了为什么扩散草稿生成方式能够同时实现低草稿延迟和高接受率。
3.1 Speculative Decoding Speedup
推测性解码利用较小的草稿模型 来加速目标模型 的推理。在每个解码周期中,草稿模型提出 个 token,这些 token 由目标模型并行验证。
继 Sadhukhan et al. (2025),每个 token 的平均延迟是
其中, 表示生成草稿 token 所花费的时间, 表示验证成本, 表示每个解码周期内被接受的 token 的预期数量,包括目标模型生成的奖励 token。令 表示 的自回归单 token 延迟;由此得到的加速比为 。
该表达式明确地表达了权衡:提高速度要么通过增加预期接受长度 ,要么通过减少草稿开销 。
3.2 Autoregressive vs. Diffusion Drafting
自回归草稿模型按顺序生成 token,其成本为:
其中 是单次前向传递的延迟。因此,drafting 成本随预算 线性增长。
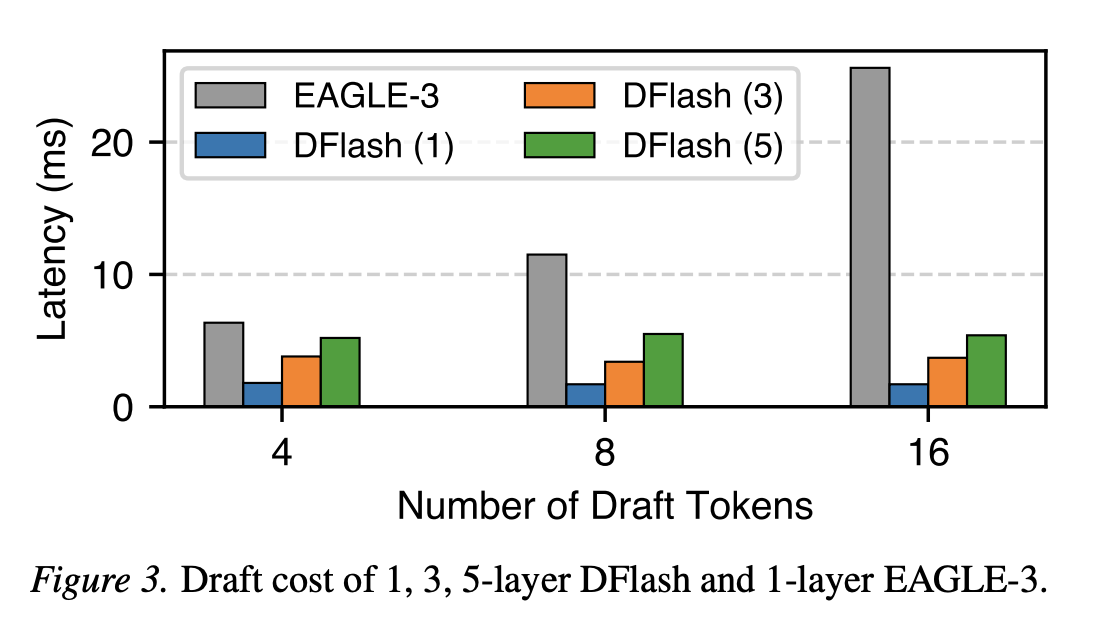
为了控制延迟,自回归草稿模型被限制在非常浅的架构上(例如,EAGLE-3 中的单层 Transformer)。这严重限制了 token 生成质量:虽然增加 会增加生成成本,但由于模型容量有限,接受长度 会迅速饱和。实际上,这种不平衡限制了可实现的加速比。
扩散草稿模型在一次前向传递中并行生成所有 token,从而产生:
其中 表示块生成的延迟。现代 GPU 执行此类并行操作的效率远高于多次顺序执行,因此对于规模相近的模型,。因此,对于中等大小的块, 对 基本不敏感。
这种并行性从根本上改变了设计空间。由于草稿 token 成本不再随生成的 token 数量而增加,扩散草稿模型可以在不牺牲延迟的情况下构建更深、更具表现力的架构。这种容量的提升显著提高了生成质量和接受时间。经验表明,一个生成 16 个 token 的五层 DFlash 草稿模型比生成 8 个 token 的 EAGLE-3 草稿模型实现了更低的延迟(图 3)和更长的接受时间,这使得 DFlash 在草稿生成质量和草稿生成成本之间处于更有利的帕累托前沿。
4.Method
4.1 Inference
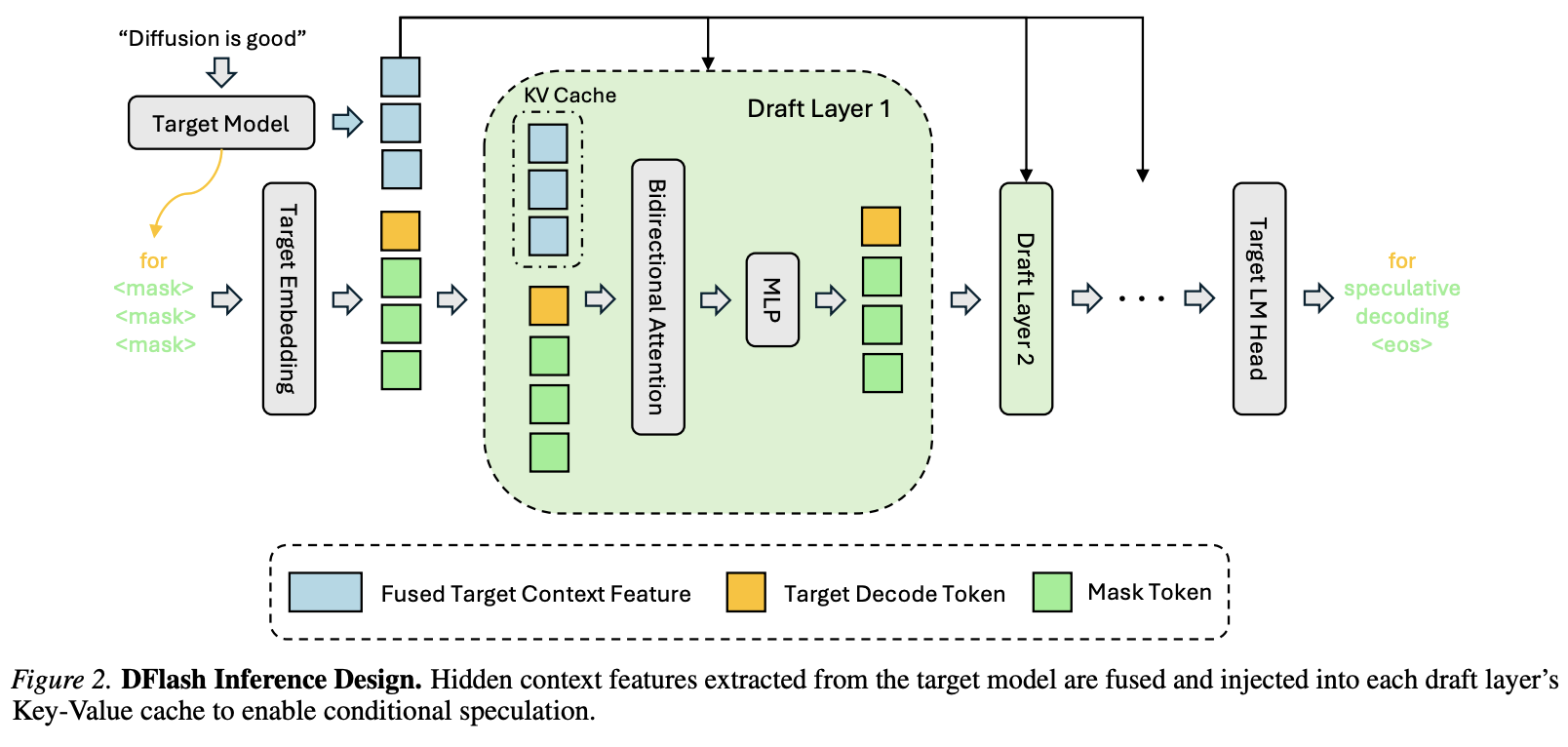
DFlash 的系统设计如图 2 所示。在本节中,我们将解释关键的设计选择,这些选择使得 DFlash 能够使用非常小巧高效的草稿模型实现高接受长度。
Context features from the target model。先前的研究,例如 An et al. (2025) ,简单地将一个小型扩散模型用作推测性草稿生成器,导致接受长度较短且加速效果有限。为了验证这一点,我们训练了一个五层块扩散草稿模型,该模型不依赖目标模型的任何条件,并在多个数学基准测试中对其进行了评估。如表 8 所示,加速效果并不显著,通常在 2-3 倍左右。这种局限性源于缺乏丰富的上下文指导:由于无法访问目标模型的内部表示,扩散草稿生成器实际上必须从头开始预测未来的 token。
相比之下,大型自回归目标模型的隐藏表示编码的信息量远大于 token 级 logit 值。这些特征捕捉了远距离依赖关系和特定任务的语义,并且——至关重要的是——隐式地编码了有关未来 token 预测的信息,正如 Samragh et al. (2025) 所观察到的那样。
在 DFlash 中,给定一个输入提示,目标模型首先执行标准的预填充过程以生成第一个 token。在此过程中,我们从一组固定的层中提取隐藏表示,这些层从浅层到深层均匀采样。
Conditioning via KV injection enables acceptance scaling。现有方法(例如 EAGLE-3)也利用目标模型中的隐藏特征,但它们将这些特征与草稿模型的词嵌入融合,并仅作为草稿模型的输入。随着草稿模型深度的增加,来自目标模型的信息会被不断稀释,导致增加草稿层数时,接受长度的提升效果逐渐减弱。
DFlash 采用了一种截然不同的策略。我们将融合后的目标上下文特征视为持久化的上下文信息,并将其直接注入到每个草稿模型层的 key-value 投影中。投影后的特征存储在草稿模型的 key-value 缓存中,并在草稿迭代中重复使用。这种设计在整个草稿模型中提供了强大且一致的条件,使得接受长度能够随着草稿层数的增加而有效扩展。我们将在 5.4.2 节中更详细地分析这种行为。
Parallel diffusion drafting。DFlash 速度快的另一个关键因素是其低延迟的草稿生成。自回归草稿模型必须执行多次顺序前向传播才能生成 token 序列或树,这限制了并行性,导致 GPU 利用率低下。相比之下,DFlash 使用块级扩散过程来预测下一个 token 块。块内所有掩码位置都在一次前向传播中并行解码。与自回归草稿模型相比,这种逐块并行生成方式显著降低了草稿生成延迟,并实现了更高的硬件利用率,即使使用更深的草稿模型也是如此。
总体而言,DFlash 将基于扩散的并行草稿生成与目标模型的紧密耦合条件相结合,从而能够实现高质量的草稿生成,并大幅降低生成延迟。
4.2 Training

DFlash 的草稿模型经过训练,可将块级扩散预测与冻结的自回归目标模型的输出对齐。我们并未直接采用标准的块扩散训练方法,而是引入了几项关键改进,以提高训练效率、可扩展性以及与推理时推测性解码行为的一致性。
KV injection。类似于推理流程,给定一个由提示及其响应组成的序列,我们首先将整个干净的序列输入目标模型,以提取并融合所有 token 的隐藏特征。然后,如图 4 所示,这些隐藏特征作为 key-value 对投影注入到草稿模型中。
Random sampling of masked blocks。在标准块扩散训练中,响应被均匀地分成若干块,每个块内的随机位置被 mask,模型被训练来对 mask 的标记进行去噪。
DFlash 则针对推测性解码场景定制了块构建方式。我们从响应中随机抽取锚 token,并将每个锚标记用作块的起始位置,同时屏蔽剩余位置。草稿模型并行训练,以预测块大小减 1 个 token。这与推理时的行为直接匹配,草稿模型始终以目标模型生成的干净 token(即上一步验证步骤中的奖励 token)为条件。随机化锚 token 位置还能使草稿模型接触到更多样化的目标上下文特征,从而提高数据效率和覆盖率。如表 9 所示,该策略显著缩短了接受长度并提高了加速比。
在训练过程中,所有块被连接成一个序列,并使用稀疏注意力 mask进行联合处理,如图 4 所示。token 在同一模块内以及相应的注入目标上下文特征之间进行双向注意力,但不允许跨模块的注意力。这种设计使得可以使用 Flex Attention 在一次前向和后向传播中高效地训练多个草稿模块。
Efficient long-context training。由于 EAGLE-3 等方法需要耗费大量训练时间进行测试,因此在长上下文数据上训练推测性草稿模型极具挑战性。DFlash 通过固定每个序列的扩散块数量,并在每个训练 epoch 中随机采样每个序列的锚框位置,实现了高效的长上下文训练。这种策略在有效增强数据的同时,还能将训练成本控制在合理范围内。
Loss weighting for faster convergence。在推测性解码中,并非所有 token 都同等重要。草稿块早期位置的错误会使所有后续 token 失效。这使得早期预测对接受长度的影响尤为重要。我们通过调整交叉熵损失的权重来反映这种不对称性,从而在训练过程中更加重视早期 token 的位置。
具体而言,对于块内位置为 的 token,我们应用指数衰减的权重。
其中 控制衰减率。这种加权方式优先考虑早期位置,加快收敛速度,并产生比均匀加权更高的接受长度(图 5)。
Shared embedding and LM head。为了提高训练效率,草稿模型与目标模型共享词嵌入层和语言建模头,并在训练过程中保持冻结状态。仅更新草稿模型的 Transformer 层。这种设计减少了可训练参数的数量,并使草稿模型能够作为轻量级扩散适配器,与目标模型的表示空间紧密对齐。
5.Experiments